Documentation Index
Fetch the complete documentation index at: https://docs.scaledown.ai/llms.txt
Use this file to discover all available pages before exploring further.
Overview
Created as part of Eleuther SOAR by Nadya Devani, Pouya Sadeghi, Purva Kandalgaonkar, Suparnojit Sarkar
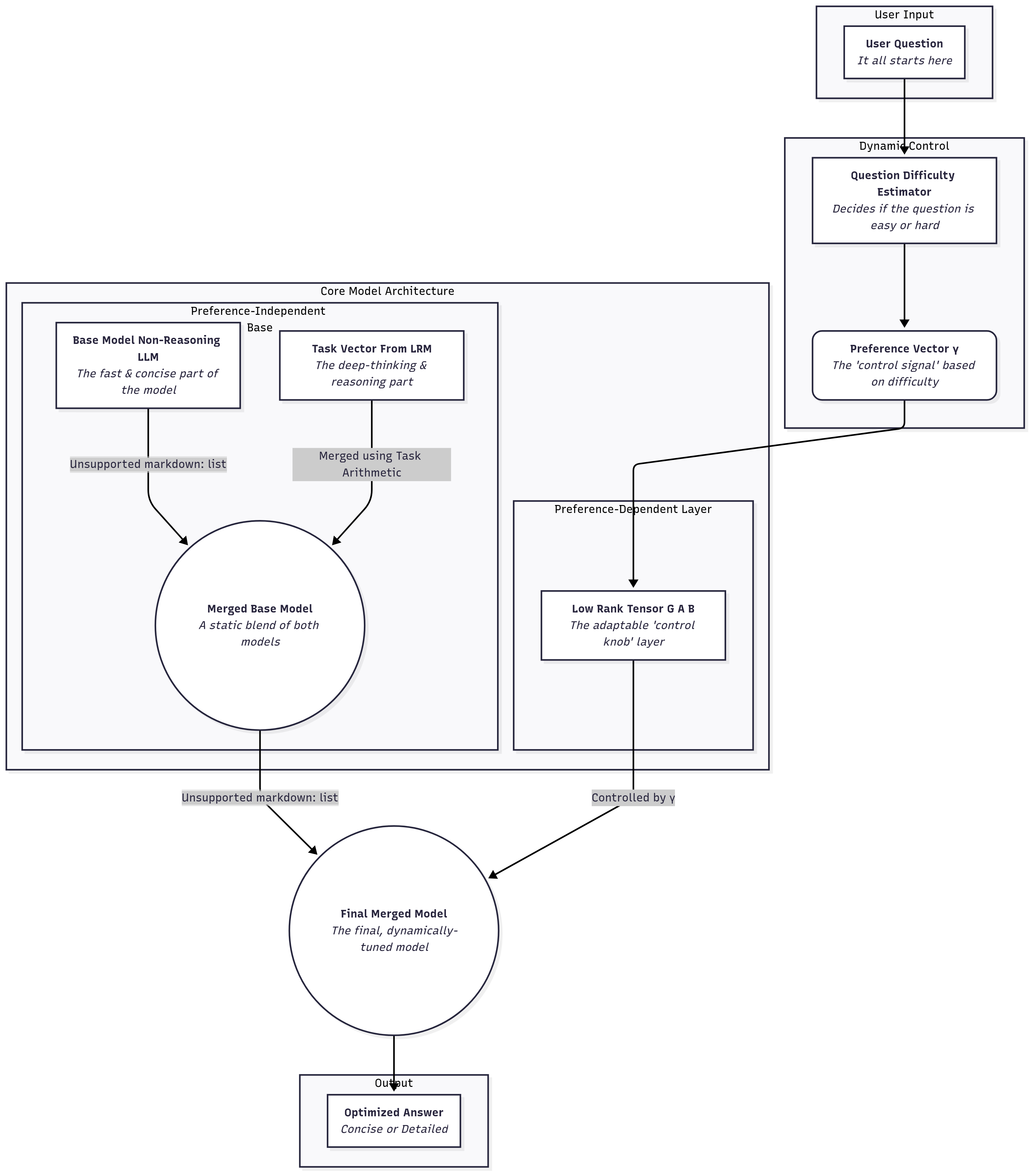
The Pareto Merging method is an advanced technique for combining multiple specialized AI models into a single, highly efficient model. Unlike traditional methods that create one static merged model, Pareto Merging produces a flexible framework that can generate an infinite number of model variations tailored to specific needs without retraining. This method merges two types of models: a concise, non-reasoning Large Language Model (LLM) and a powerful Large Reasoning Model (LRM). The key innovation is a two-part architecture:- Preference-Independent Base Model: A single, fixed base model combines the general knowledge of the LLM with the reasoning capabilities of the LRM.
- Preference-Dependent Tensor: A small, trainable “control knob” that is adjusted on-the-fly based on a predicted question difficulty score.
Architecture